A Comprehensive Guide to MapReduce Tutorials: Unveiling the Power of Distributed Processing
Related Articles: A Comprehensive Guide to MapReduce Tutorials: Unveiling the Power of Distributed Processing
Introduction
With enthusiasm, let’s navigate through the intriguing topic related to A Comprehensive Guide to MapReduce Tutorials: Unveiling the Power of Distributed Processing. Let’s weave interesting information and offer fresh perspectives to the readers.
Table of Content
- 1 Related Articles: A Comprehensive Guide to MapReduce Tutorials: Unveiling the Power of Distributed Processing
- 2 Introduction
- 3 A Comprehensive Guide to MapReduce Tutorials: Unveiling the Power of Distributed Processing
- 3.1 Understanding MapReduce: A Foundation for Parallel Processing
- 3.2 Advantages of MapReduce: Harnessing the Power of Distributed Processing
- 3.3 Exploring MapReduce Tutorials: A Hands-on Approach to Mastering the Paradigm
- 3.4 Popular MapReduce Implementations: Exploring the Landscape of Tools and Frameworks
- 3.5 FAQs on MapReduce Tutorials: Addressing Common Questions and Concerns
- 3.6 Tips for Mastering MapReduce Tutorials: A Guide to Effective Learning
- 3.7 Conclusion: MapReduce – A Foundation for Big Data Processing
- 4 Closure
A Comprehensive Guide to MapReduce Tutorials: Unveiling the Power of Distributed Processing
The world of big data is vast and complex, demanding efficient and scalable solutions for handling massive datasets. This is where MapReduce emerges as a powerful paradigm, enabling parallel processing across distributed systems. This guide delves into the intricacies of MapReduce, providing a comprehensive understanding of its principles, applications, and implementation through tutorials.
Understanding MapReduce: A Foundation for Parallel Processing
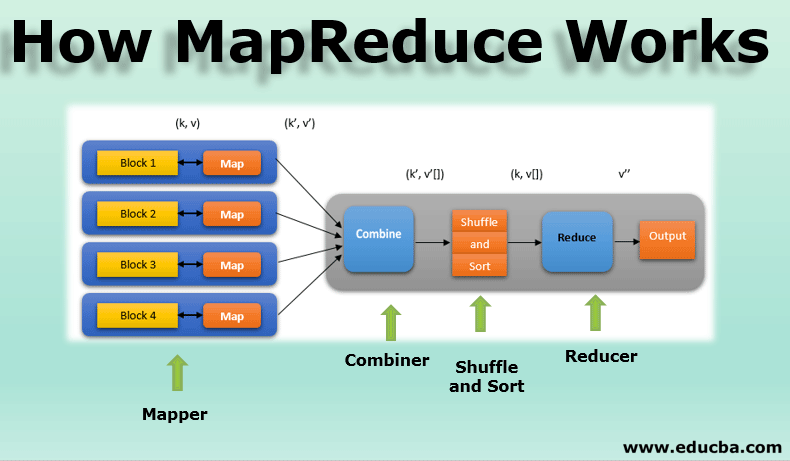
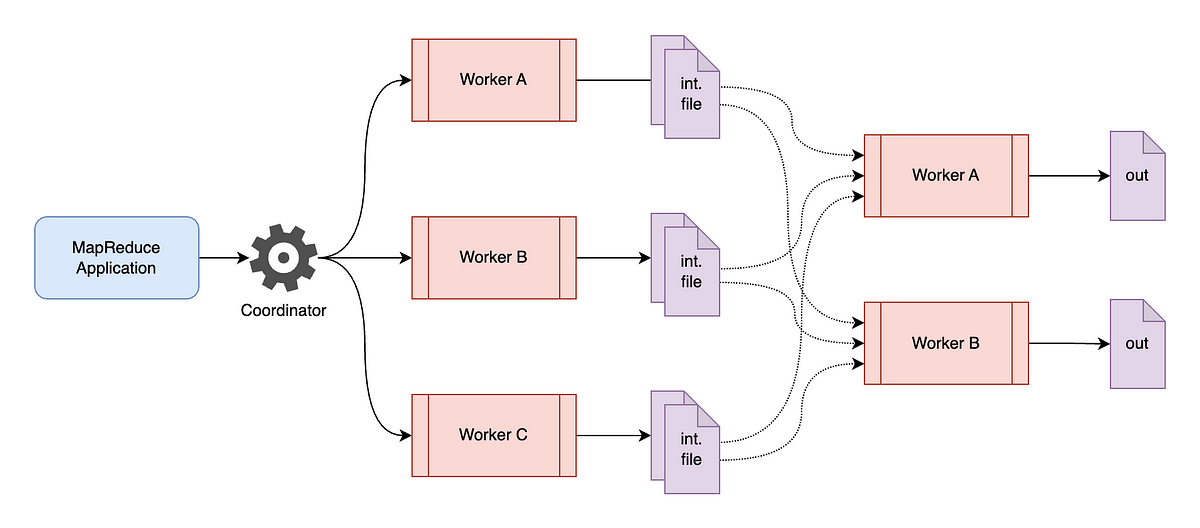
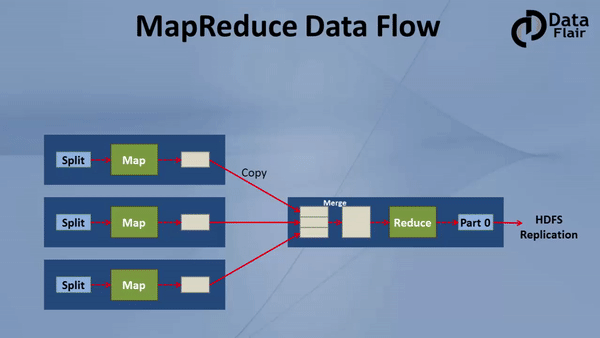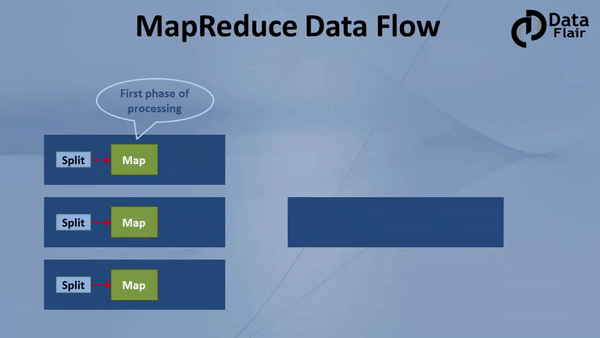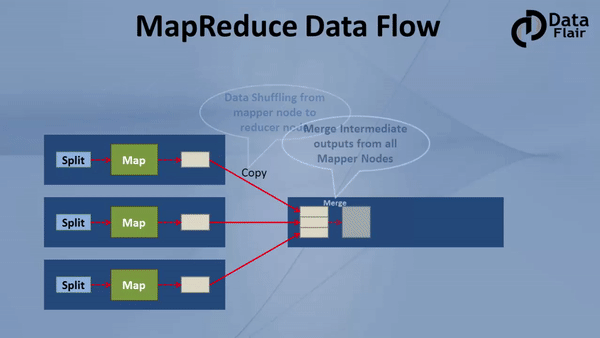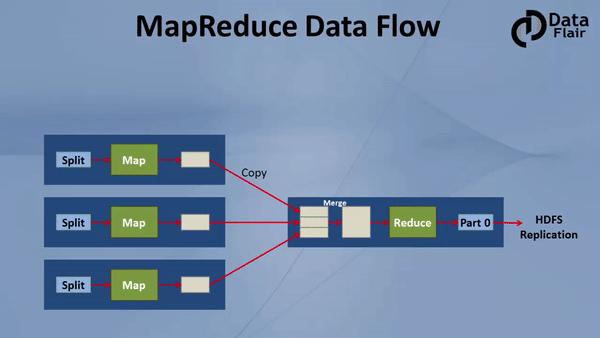
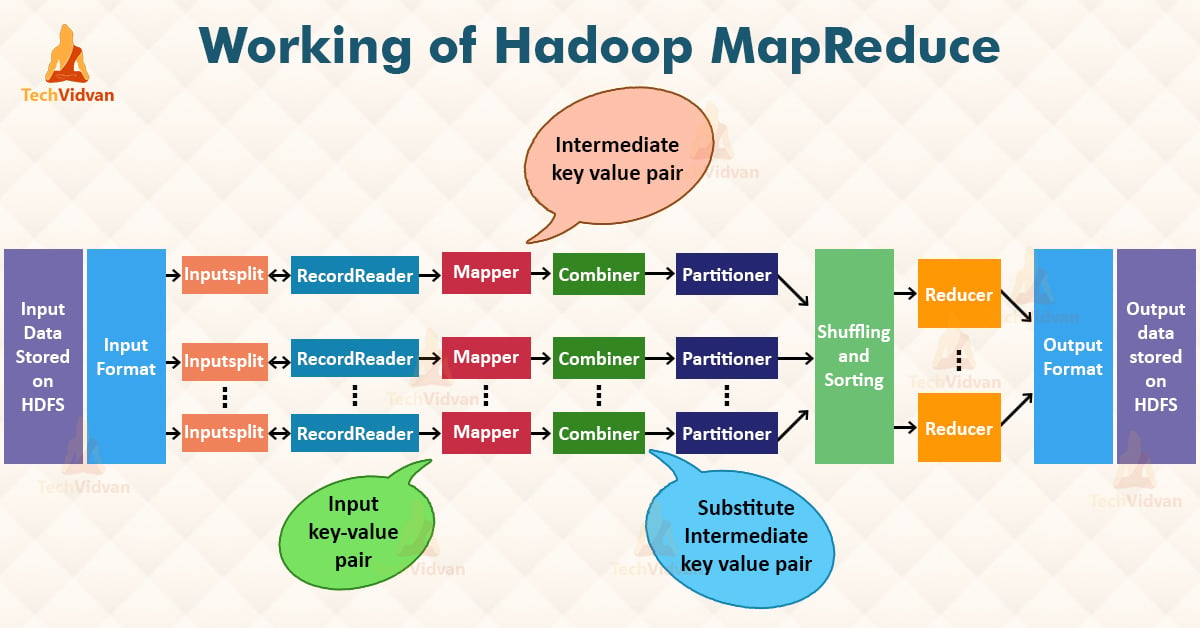
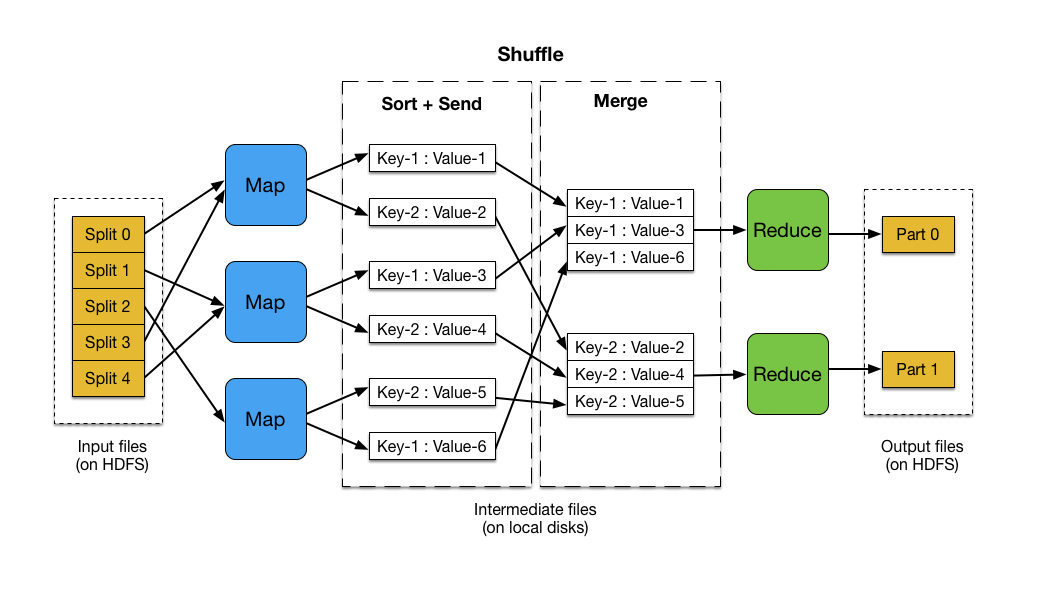
MapReduce, at its core, is a programming model designed for distributed processing of large datasets. It simplifies the process of parallelizing tasks across multiple nodes in a cluster, effectively handling the complexity of data distribution and coordination.
The model operates in two distinct phases:
- Map Phase: This phase involves dividing the input dataset into smaller chunks, each processed independently by a map function. The map function transforms each chunk into key-value pairs, facilitating data aggregation and analysis.
- Reduce Phase: The key-value pairs generated in the map phase are then grouped by their keys. A reduce function is applied to each group, combining the values associated with the same key, producing a final output.
Advantages of MapReduce: Harnessing the Power of Distributed Processing
MapReduce offers several advantages that make it a valuable tool for big data processing:
- Scalability: The inherent parallelism of MapReduce allows for easy scaling of processing power by adding more nodes to the cluster. This ensures efficient handling of datasets that grow exponentially.
- Fault Tolerance: MapReduce is designed to be resilient to node failures. The framework automatically replicates data and tasks, ensuring the completion of processing even if a node goes down.
- Simplicity: The MapReduce model abstracts away the complexities of distributed processing, allowing developers to focus on the core logic of their algorithms.
- Flexibility: The framework is versatile enough to handle a wide range of data processing tasks, including sorting, filtering, aggregation, and joining.
Exploring MapReduce Tutorials: A Hands-on Approach to Mastering the Paradigm
Learning MapReduce effectively requires practical experience. Numerous tutorials are available online and through various platforms, providing a hands-on approach to understanding and implementing the framework. These tutorials offer valuable insights into:
- Basic Concepts: A thorough understanding of the MapReduce paradigm, including its core phases, key-value pairs, and input/output formats.
- Practical Implementation: Step-by-step guides on setting up a MapReduce environment, writing map and reduce functions, and executing tasks on a cluster.
- Real-World Applications: Examples demonstrating how MapReduce can be applied to solve various data processing challenges, such as web analytics, social media analysis, and scientific data processing.
Popular MapReduce Implementations: Exploring the Landscape of Tools and Frameworks
Several popular implementations of MapReduce have emerged over the years, each with its own strengths and features:
- Hadoop: An open-source framework that provides a robust platform for implementing MapReduce applications. It offers a distributed file system (HDFS) for data storage and a resource manager (YARN) for task scheduling.
- Apache Spark: A fast and general-purpose cluster computing framework that offers a more versatile approach to data processing, supporting both batch and real-time processing.
- Amazon EMR: A cloud-based service that simplifies the deployment and management of Hadoop and Spark clusters on Amazon Web Services (AWS).
FAQs on MapReduce Tutorials: Addressing Common Questions and Concerns
Q: What are the prerequisites for learning MapReduce?
A: A basic understanding of programming concepts, including data structures and algorithms, is recommended. Familiarity with Java or Python programming languages is also helpful, as they are commonly used for developing MapReduce applications.
Q: What are the best resources for learning MapReduce?
A: Numerous online resources, including tutorials, documentation, and courses, are available. Some popular options include:
- Apache Hadoop Documentation: https://hadoop.apache.org/docs/
- Apache Spark Documentation: https://spark.apache.org/docs/
- Coursera Courses: https://www.coursera.org/
- Udemy Courses: https://www.udemy.com/
Q: How do I choose the right MapReduce implementation for my needs?
A: The choice of implementation depends on factors such as the size and type of data, the processing requirements, and the availability of resources. For large-scale batch processing, Hadoop is a suitable option. For real-time processing and more versatile data analysis, Apache Spark is often preferred.
Q: What are the challenges of working with MapReduce?
A: While MapReduce offers significant advantages, it also presents some challenges:
- Complexity: Setting up and managing a distributed cluster can be complex, requiring expertise in system administration.
- Performance: For certain types of data processing, particularly real-time applications, MapReduce might not be the most efficient solution.
- Data Consistency: Maintaining data consistency across multiple nodes can be challenging in a distributed environment.
Tips for Mastering MapReduce Tutorials: A Guide to Effective Learning
- Start with the Basics: Begin by understanding the fundamental concepts of MapReduce, including the map and reduce phases, input/output formats, and data partitioning.
- Practice with Simple Examples: Start with small-scale examples to get a feel for the framework and its functionalities. Gradually move towards more complex problems as you gain experience.
- Utilize Online Resources: Leverage online tutorials, documentation, and forums to clarify concepts and resolve issues.
- Experiment and Explore: Don’t be afraid to experiment with different approaches and explore the capabilities of the framework.
Conclusion: MapReduce – A Foundation for Big Data Processing
MapReduce has revolutionized big data processing, providing a powerful and scalable solution for handling massive datasets. By understanding the principles of MapReduce and leveraging the wealth of tutorials available, developers can unlock the potential of this paradigm and efficiently tackle complex data processing challenges. As the world of big data continues to evolve, MapReduce remains a foundational technology, paving the way for innovative solutions and advancements in data analysis.



Closure
Thus, we hope this article has provided valuable insights into A Comprehensive Guide to MapReduce Tutorials: Unveiling the Power of Distributed Processing. We thank you for taking the time to read this article. See you in our next article!